Related Recommendation
- 해당 상품 구매가 꺼려지는 경우 연관된 다른 상품을 추천해주는 방법
"Transaction Data에서의 아이템 연관성 추출"
- 사용자 : 동일 사용자가 같이 본 아이템들은 연관성 존재
- 세션 : 동일 세션에서 같이 조회한 아이템들은 연관성 존재
- 인접 : 동일 사용자 로그의 인접한 아이템들은 연관성 존재
연관성 추출 기준

- 세션 기준이 경험상 가장 정확함.
유사도 지표

- 특별한 경우가 아니라면 코사인 유사도가 가장 유용함
가중치 할당
- 대중적인 아이템은 조회나 접근 횟수가 많아 단순 카운팅 기반으로 가중치를 부여할 경우 이상 현상이 발생할 수 있음
- 가중치를 0,1로만 한정할 수 있음
- 최대값을 한정하여 이상치를 조절할 수 있음
- 횟수에 로그를 취하여 영향을 조절할 수 있음
Case Study
A1. Co-occurrence with Frequency Counts
- 단일상품주문이 많아,사용자 단위로 데이터를 묶음
- 한 사용자가 함께 구매한 상품의 횟수를 기준으로 연관 결과를 생성
A2. Co-occurrence with Frequency Counts - IDF
- 위 A1 결과에서 자주 구매한 상품의 가중치를 낮추기 위해 IDF를 도입하여 개선
A3. Co-occurrence with Normalized Frequency Counts - IDF
- 위 A2 결과에서 너무 많이 구매된 상품(e.g., 아메리카노)의 이상치를 낮추기 위해 로그(log) 값으로 표준화
A4. Cosine Similarity with Binary Counts
- 두 상품의 유사도를 계산하는데 코사인 유사도(cosine similarity)를 활용
- 이때, 상품 횟수를 고려하지않고 구매가 발생되면 1로 통일하여 사용
A5. Cosine Similarity with Frequency Counts
- 위 A4 결과에서 구매 횟수를 고려 하여 코사인 유사도 계산
A6. Cosine Similarity with Normalized Frequency Counts ‒ IDF
- 위 A5 결과에서 IDF를 적용하여 자주 구매한 상품의 가중치를 낮춤
추천 결과가 부족한 경우
1. Content-based Related Recommendation 결과 활용
• 영화, 뉴스와 같이 메타데이터가 풍부한 경우 잘 동작함
2. Best Recommendation 결과를 보완 로직으로 활용
• 같은 카테고리의 베스트 상품 노출
3. 추천 결과의 연관 상품까지 결과로 활용
4. SVD 등Matrix Factorization 방법 활용
사용자 기준 Related Product
- 유저 기준으로 아이템이 얼마나 클릭이 되는지 확인
%%sql
drop table if exists cmc_user_product_click_cnt;
create table cmc_user_product_click_cnt as
select user_no, item_no, count(*) cnt
from cmc_event a
where event_name = 'click_item'
and a.event_timestamp between '2021-07-18' and '2021-07-25'
group by user_no, item_no;- 클릭 분포 확인
query = '''
select cnt, count(*)
from cmc_user_product_click_cnt
group by cnt;
'''
res1 = executeQuery(query)
import pandas as pd
df = pd.DataFrame(res1, columns=['cnt', 'count'])
df.plot.bar(x='cnt', y='count', rot=0, figsize=(20,5))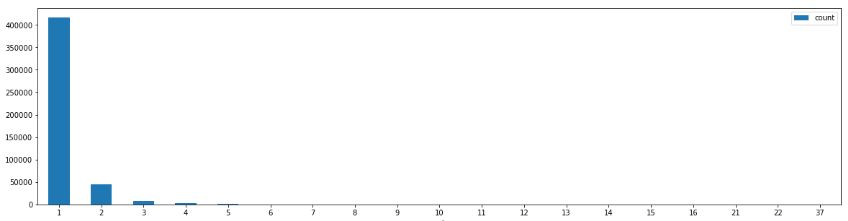
사용자 클릭 가중치 테이블 생성(normalized)
- count값을 활용하여 weight값 생성
%%sql
drop table if exists cmc_user_product_click_w;
create table cmc_user_product_click_w as
-- normalized
select user_no, item_no, w/sqrt(sum(w*w) over (partition by user_no)) w
from (
select user_no, item_no, (ln(cnt)+1) w --ln(cnt+1)로 사용해도 된다
from cmc_user_product_click_cnt ) t;
-- user를 기준으로 access 하기 위한 index 생성
create index idx_cmc_user_product_click_w_1 on cmc_user_product_click_w (user_no, item_no, w);
-- item를 기준으로 access 하기 위한 index 생성
create index idx_cmc_user_product_click_w_2 on cmc_user_product_click_w (item_no, user_no, w);
"item_no = '6tt2Q2Jveb2qyFrH78Fwqw=='"

Co-Occurance 유사도 지표를 활용한 연관 상품 추천
item_no = '6tt2Q2Jveb2qyFrH78Fwqw=='
result = %sql select * from cmc_product where item_no = :item_no;
-- self join으로 weight값 계산
query1 = f'''
with cmc_product_sim as (
select b.item_no, count(*) sim -- co-occur방법
from cmc_user_product_click_w a
join cmc_user_product_click_w b
on a.user_no = b.user_no
and a.item_no != b.item_no
where a.item_no = '{item_no}'
group by b.item_no
order by sim desc
limit 20)
select a.sim, b.*
from cmc_product_sim a
join cmc_product b on b.item_no = a.item_no
'''
result1 = executeQuery(query1)
유사도 방법을 활용한 연관 상품 추천
query2 = '''
with cmc_product_sim as (
select b.item_no, sum(a.w * b.w) sim -- 유사도 방법
from cmc_user_product_click_w a
join cmc_user_product_click_w b on a.user_no = b.user_no and a.item_no != b.item_no
where a.item_no = '{item_no}'
group by b.item_no
order by sim desc
limit 20)
select a.sim, b.*
from cmc_product_sim a
join cmc_product b on b.item_no = a.item_no
'''
result2 = executeQuery(query2)
세션 기준 Related Product
%%sql
drop table if exists cmc_session_product_click_cnt;
create table cmc_session_product_click_cnt as
select session_id, item_no, count(*) cnt
from cmc_event a
where event_name = 'click_item'
and a.event_timestamp between '2021-07-18' and '2021-07-25'
group by session_id, item_no;
- 클릭 분포 확인
query = '''
select cnt, count(*)
from cmc_session_product_click_cnt
group by cnt;
'''
res1 = executeQuery(query)
df = pd.DataFrame(res1, columns=['cnt', 'count'])
df.plot.bar(x='cnt', y='count', rot=0, figsize=(20,5))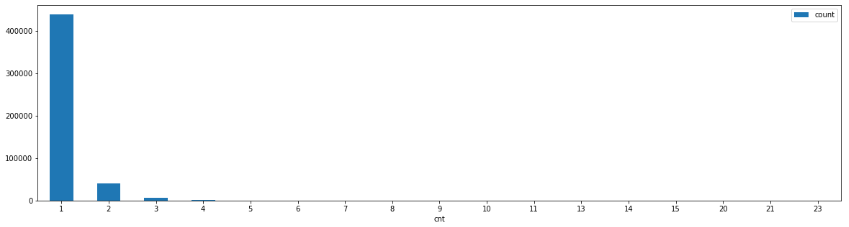
세션 클릭 가중치 테이블 생성(normalized)
%%sql
drop table if exists cmc_session_product_click_w;
create table cmc_session_product_click_w as
select session_id, item_no, w/sqrt(sum(w*w) over (partition by session_id)) w
from (
select session_id, item_no, (ln(cnt)+1) w
from cmc_session_product_click_cnt ) t;
create index idx_cmc_session_product_click_w_1 on cmc_session_product_click_w (session_id, item_no, w);
create index idx_cmc_session_product_click_w_2 on cmc_session_product_click_w (item_no, session_id, w);Co-Occurance 유사도 지표를 활용한 연관 상품 추천
result = %sql select * from cmc_product where item_no = :item_no;
query3 = f'''
with cmc_product_sim as (
select b.item_no, count(*) sim -- sum(a.w * b.w) sim
from cmc_session_product_click_w a
join cmc_session_product_click_w b on a.session_id = b.session_id and a.item_no != b.item_no
where a.item_no = '{item_no}'
group by b.item_no
order by sim desc
limit 10)
select a.sim, b.*
from cmc_product_sim a
join cmc_product b on b.item_no = a.item_no
'''
result3 = executeQuery(query3)
유사도 방법을 활용한 연관 상품 추천
query4 = f'''
with cmc_product_sim as (
select b.item_no, sum(a.w * b.w) sim
from cmc_session_product_click_w a
join cmc_session_product_click_w b on a.session_id = b.session_id and a.item_no != b.item_no
where a.item_no = '{item_no}'
group by b.item_no
order by sim desc
limit 10)
select a.sim, b.*
from cmc_product_sim a
join cmc_product b on b.item_no = a.item_no
'''
result4 = executeQuery(query4)
Consider Popularity
- idf값을 고려
%%sql
drop table if exists cmc_session_product_click_w2;
--idf값이 반영된 weight 구하기
create table cmc_session_product_click_w2 as
with df as (
select session_id, count(*) df
from cmc_session_product_click_cnt
group by session_id )
select session_id, item_no, w/sqrt(sum(w*w) over (partition by session_id)) w
from (
select a.session_id, a.item_no, (ln(cnt)+1)*ln(100200.0/df + 1.0) w --적당한 값을 넣으면 상관 없음
from cmc_session_product_click_cnt a left join df b on a.session_id = b.session_id
) t;
create index idx_cmc_session_product_click_w2_1 on cmc_session_product_click_w2 (session_id, item_no, w);
create index idx_cmc_session_product_click_w2_2 on cmc_session_product_click_w2 (item_no, session_id, w);
query5 = f'''
with cmc_product_sim as (
select b.item_no, sum(a.w * b.w) sim
from cmc_session_product_click_w2 a
join cmc_session_product_click_w2 b on a.session_id = b.session_id and a.item_no != b.item_no
where a.item_no = '{item_no}'
group by b.item_no
order by sim desc
limit 20)
select a.sim, b.*
from cmc_product_sim a
join cmc_product b on b.item_no = a.item_no
'''
result5 = executeQuery(query5)
대체제
- 상품정보(b)에서 카테고리에 대한 한정을 추가하면 된다.
query6 = f'''
with cmc_product_sim as (
select b.item_no, sum(a.w * b.w) sim
from cmc_session_product_click_w2 a
join cmc_session_product_click_w2 b on a.session_id = b.session_id and a.item_no != b.item_no
where a.item_no = '{item_no}'
group by b.item_no
order by sim desc)
select a.sim, b.*
from cmc_product_sim a
join cmc_product b on b.item_no = a.item_no
-- 아이템의 카테고리와 같은 카테고리의 아이템들 중에서 추천
where b.category3_code = (select category3_code from cmc_product where item_no = '{item_no}')
order by a.sim desc
limit 20
'''
result6 = executeQuery(query6)
보완제
- 카테고리가 다른 것으로 한정하여 추천(category3으로 하면 신발도 나오기 때문에 더 상위 카테고리인 category2로 하는것이 좋음)
query7 = f'''
with cmc_product_sim as (
select b.item_no, sum(a.w * b.w) sim
from cmc_session_product_click_w2 a
join cmc_session_product_click_w2 b on a.session_id = b.session_id and a.item_no != b.item_no
where a.item_no = '{item_no}'
group by b.item_no
order by sim desc)
select a.sim, b.*
from cmc_product_sim a
join cmc_product b on b.item_no = a.item_no
where b.category2_code != (select category2_code from cmc_product where item_no = '{item_no}')
order by a.sim desc
limit 20
'''
result7 = executeQuery(query7)
출처 : The RED : 현실 데이터를 활용한 추천시스템 구현 A to Z by 번개장터 CTO 이동주
'Learning > Recommendation System' 카테고리의 다른 글
| 04-1. 고급 추천(Beyond Accuracy) (0) | 2022.06.13 |
|---|---|
| 03-4. Personalized Recommendation (0) | 2022.06.02 |
| 03-2. Best Recommendation (0) | 2022.06.02 |
| 03-1. E-commerce 상품 추천(트랜잭션 데이터 기반) (0) | 2022.05.16 |
| 02-3. CF 기반 평점 예측을 이용한 영화 추천 (0) | 2022.05.12 |