Item-based Collaborative Filtering
가정 : 유사한 아이템(ex. 평점을 부여한 패턴)에 내가 부여한 평점과 비슷한 평점을 부여
다시 이해해보기 CBF vs CF
1. CBF 기반 아이템유사도: 아이템간의 유사도를 아이템 속성(메타데이터 ex.장르)을 이용하여 계산
Step 1 : TF-IDF를 이용하여 아이템을 vector로 표현
Step 2 : 아이템간의 유사도를 cosine similarity로 계산
2. CF 기반 아이템유사도: 아이템간의 유사도를 사용자의 아이템 평가 이력을 이용하여 계산
Step 1 : 평점데이터를 이용하여 아이템을 vector로 표현
Step 2 : 아이템간의 유사도를 cosine(pearson) similarity로 계산

- Dimension : N(사용자수) (※CBF에서는 아이템 속성수)
- Sparse Vector : 대부분의 element 값이 비어 있음(NULL)
Item-Item Cosine similarity

- Null Value Handling : 두 vector에서 모두 null이 아닌 row만 사용
(0으로 채워도 오차가 크지는 않지만 정확도가 떨어짐)

Item-Item Pearson Similarity
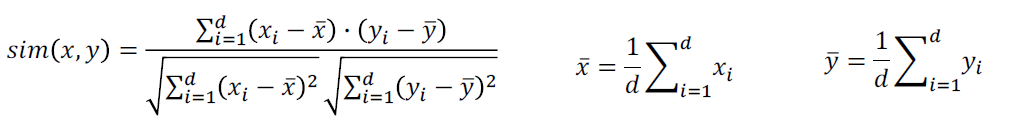

※ bar(x)는 아이템 전체 레이팅의 평균으로 구해도 되고 x,y에 공통적으로 존재하는 element의 평균으로 구해도 된다.
Rating Prediction using Item Similarity

Cosine Similarity는 항상 0보다 크기 때문에 절대값이 필요 없지만
Pearson Similarity에서는 절대값이 필요함

- 예시


- 전체 Item에 대한 Rating Prediction

Su : Similarity Matrix 중에서 사용자가 평가한 Item에 해당하는 row만..!


평점을 Item-User Sparse Matrix로 변환
- movieID to Index
movieIds = train.movieId.unique()
movieIdToIndex = {}
indexToMovieId = {}
rowIdx = 0
for movieId in movieIds:
movieIdToIndex[movieId] = rowIdx
indexToMovieId[rowIdx] = movieId
rowIdx += 1- index to movieID
userIds = train.userId.unique()
userIdToIndex = {}
indexToUserId = {}
colIdx = 0
for userId in userIds:
userIdToIndex[userId] = colIdx
indexToUserId[colIdx] = userId
colIdx += 1movieIdToIndex = {31:0, 1061:1, 1129:2, ......}
indexToMonieId = {0:31, 1:1061, 2:1129, .....,}
Sparse Matrix는 대부분의 값이 0이기 때문에 연산 시 필요없는 부분이 많기 때문에 관리가 필요하다.
관리 방법 : CSR(Compressed Sparse Row), CRS(Compressed Row Storage), Yale format 등
item-user Sparse Matrix 생성
import scipy.sparse as sp
rows = []
cols = []
vals = []
for row in train.itertuples():
rows.append(movieIdToIndex[row.movieId])
cols.append(userIdToIndex[row.userId])
vals.append(row.rating)
coomat = sp.coo_matrix((vals, (rows, cols)), shape=(rowIdx, colIdx))
matrix = coomat.todense()
matrixItem-Item Similarites 계산
- l2 norm 계산
from numpy import linalg as LA
norms = LA.norm(matrix, ord = 2, axis=1)
norms
- Row Vectors 정규화
normmat = np.divide(matrix.T, norms).T # normalize된 matrics
normmat
- 내적을 통해 유사도 계산
sims = pd.DataFrame(data = np.matmul(normmat, normmat.T), index = movieIds, columns=movieIds)
sims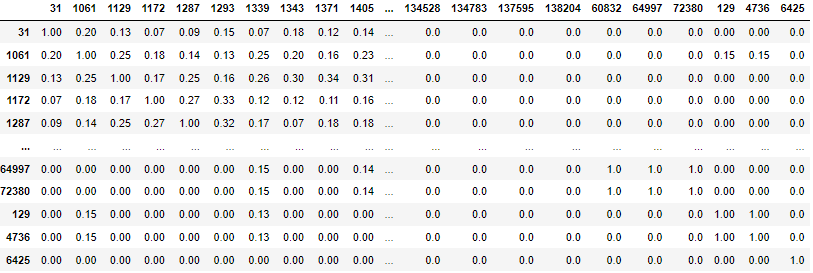
movieIdx 6의 유사도 예시
movieIdx = 6
rels = sims.iloc[movieIdx,:].sort_values(ascending=False).head(6)[1:]
displayMovies(movies, [indexToMovieId[movieIdx]])
displayMovies(movies, rels.index, rels.values) # index : 영화 values : 유사도

User 평점 예측
userId = 33
userRatings = train[train['userId'] == userId][['movieId', 'rating']]
recSimSums = sims.loc[userRatings['movieId'].values, :].sum().values
recWeightedRatingSums = np.matmul(sims.loc[userRatings['movieId'].values, :].T.values, userRatings['rating'].values)
recItemRatings = pd.DataFrame(data = np.divide(recWeightedRatingSums, recSimSums), index=sims.index)
recItemRatings.columns = ['pred']
- Top 30개 display
top30Movies = recItemRatings.sort_values(by='pred', ascending=False).head(30)
displayMovies(movies, top30Movies.index, top30Movies['pred'].values)오차 계산(MAE, RMSE)
userTestRatings = pd.DataFrame(data=test[test['userId'] == userId])
temp = userTestRatings.join(recItemRatings.loc[userTestRatings['movieId']], on='movieId')
mae = getMAE(temp['rating'], temp['pred'])
rmse = getRMSE(temp['rating'], temp['pred'])
print(f"MAE : {mae:.4f}")
print(f"RMSE: {rmse:.4f}")
User-Based Collaborative Filtering
가정 : 나와 유사한 사용자들의 해당 아이템 평점과 비슷하게 부여
CF 기반 사용자 유사도
- 사용자간의 유사도를 사용자의 아이템 평가 이력을 이용하여 계산
Step 1. 평점 데이터를 이용하여 사용자를 vector로 표현
Step 2. 사용자간의 유사도를 cosine(pearson) similarity로 계산
User Similarity
User-User Cosine Similarity & User-User Pearson Similarity
- Item Vector가 아닌 User Vector간에 Similarity를 계산
- Similarity 계산 공식은 Item-Item similarity에서의 공식과 동일
Rating Prediction ising User Similarity


- 예시


# Converts Ratings to User-Item Sparse Matrix
## Create Index to Id Maps
movieIds = train.movieId.unique()
movieIdToIndex = {}
indexToMovieId = {}
colIdx = 0
for movieId in movieIds:
movieIdToIndex[movieId] = colIdx
indexToMovieId[colIdx] = movieId
colIdx += 1
userIds = train.userId.unique()
userIdToIndex = {}
indexToUserId = {}
rowIdx = 0
for userId in userIds:
userIdToIndex[userId] = rowIdx
indexToUserId[rowIdx] = userId
rowIdx += 1
# Creat User-Item Sparse Matrix
rows = []
cols = []
vals = []
for row in train.itertuples():
rows.append(userIdToIndex[row.userId])
cols.append(movieIdToIndex[row.movieId])
vals.append(row.rating)
coomat = sp.coo_matrix((vals, (rows, cols)), shape=(rowIdx, colIdx))
matrix = coomat.todense()
# Compute User-User Similarities
## Compute 𝑙2 -norm
norms = LA.norm(matrix, ord = 2, axis=1)
## Normalize Row Vectors
normmat = np.divide(matrix.T, norms).T
## Compute Similarities ( = inner product)
sims = pd.DataFrame(data = np.matmul(normmat, normmat.T), index = userIds, columns=userIds)- Example
userId = 33
topK = 5
simUsers = sims.loc[userId, :].sort_values(ascending=False).head(6).tail(5) # 유사도가 큰 유저 6명 추출(tail은 33본인은 제외)
def displayLikedUserMovies(movies, userId, topK):
topKRatings = train[train['userId'] == userId].sort_values(by='rating', ascending=False).head(topK)
display(HTML(f"<h3>{userId}</h3><hr>"))
displayMovies(movies, topKRatings.movieId.values, topKRatings.rating.values)
for index, simUser in simUsers.iteritems():
displayLikedUserMovies(movies, index, topK)- User 평점 예측
userId = 33
ratingDF = pd.DataFrame(data=matrix, index=userIds, columns=movieIds)
binDF = ratingDF.applymap(lambda x: math.ceil(x/10)) # rating이 있는곳만 1로 처리 0이 있는값들을 평균에 안넣기 위함
userAvgRatings = pd.DataFrame(data = ratingDF.sum(axis=1).divide(binDF.sum(axis=1)), columns=['avg'])
simUsers = sims.loc[userId, :]
simUsers[userId] = 0
simRatingSums = (ratingDF - binDF.T.multiply(userAvgRatings['avg']).T).T.multiply(simUsers).T.sum(axis=0) # 분자
simSums = binDF.T.multiply(simUsers).T.sum(axis=0) # 분모
recItemRatings = userAvgRatings.loc[userId].avg + pd.Series(data = simRatingSums.divide(simSums), name='pred')
recItemRatings.fillna(0, inplace=True)
# compute Errors(MAE, RMSE)
userTestRatings = pd.DataFrame(data=test[test['userId'] == userId])
temp = userTestRatings.join(recItemRatings.loc[userTestRatings['movieId']], on='movieId')
mae = getMAE(temp['rating'], temp['pred'])
rmse = getRMSE(temp['rating'], temp['pred'])Item-based vs User-based
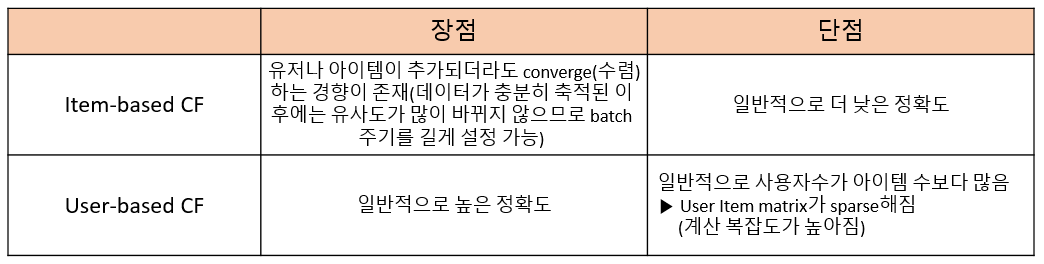
고려사항
※ Similarity 신뢰도 : Similarity 계산에 사용되는 데이터가 적은 경우(평가 이력이 적은 아이템 혹은 사용자), 유사도에 대한 신뢰도가 떨어짐.

이러한 문제를 해결하기 위해
- 평가 이력수가 적은 경우 -> 유사도 계산 X(Filtering)
- Smoothing (예 : 이력수가 K개보다 작은 경우 similarty/k 값으로 보정)
※ Rating Prediction 시 모든 아이템, 사용자에 대해 유사도를 이용하여 평점을 예측하였으나
-> 가장 유사한 Top-k 아이템 or 사용자
유사도가 특정 threshold 이상인 아이템 or 사용자 등으로 한정하기도 함. -> Similarity Matrix Storage cost를 줄임.
'Learning > Recommendation System' 카테고리의 다른 글
| 03-2. Best Recommendation (0) | 2022.06.02 |
|---|---|
| 03-1. E-commerce 상품 추천(트랜잭션 데이터 기반) (0) | 2022.05.16 |
| 02-2. CBF 기반 평점 예측을 이용한 영화 추천 (0) | 2022.05.12 |
| 02-1. 평점 예측을 이용한 영화 추천_overview (0) | 2022.05.12 |
| 01. 추천시스템 개요 (0) | 2022.05.12 |

