CBF 기반 예측
아이템 유사도 기반 평점 예측
가정 : 유사한 영화에는 유사한 평점을 부여할 것이다.

-> 아이템간 유사도를 기준으로 평점에 가중치를 부여하여 평점을 예측


>> (4*0.7 + 3*0.2 + 3*0.3 + 5*0.5) / (0.7 + 0.2 + 0.3 + 0.5) = 4
컨텐츠 기반 유사도 측정

- 두 아이템간의 유사도를 어떻게 정량화 할 것이냐가 관건
- CBF에서는 유사도를 정량화 하기 위해서 컨텐츠 자체가 가진 특성을 활용
ex.
뉴스 : 제목, 기사 내용 등
영화 : 장르, 감독, 출연자 등
상품 : 카테고리, 가격, 이미지 등
영화의 장르를 이용해 유사도 측정 - 장르의 집합으로 간주


- 대부분 자카드 유사도를 사용한다.

Distance & Similarity

Bag-of-Word Representation
TF-IDF(Term Frequency - Inverse Document Frequency)

tf(t,d) : 어떤 term이 어떠한 document에서 얼마나 중요한 것인가 계산
idf(t, D) : 전체 Document에서 term이 얼마나 중요한 의미를 갖는가 계산
TF (Term Frequency)

IDF (Inverse Document Frequency)

- 사용된 문서 집합에 존재하지 않는 단어에 대해서 IDF를 고려하게 되면 분모가 0이 되기 때문에 이를 방지하기 위해서 다음과 같이 분자, 분모에 1을 더해서 사용
TF-IDF 예제

Cosine 유사도 구하기 실습
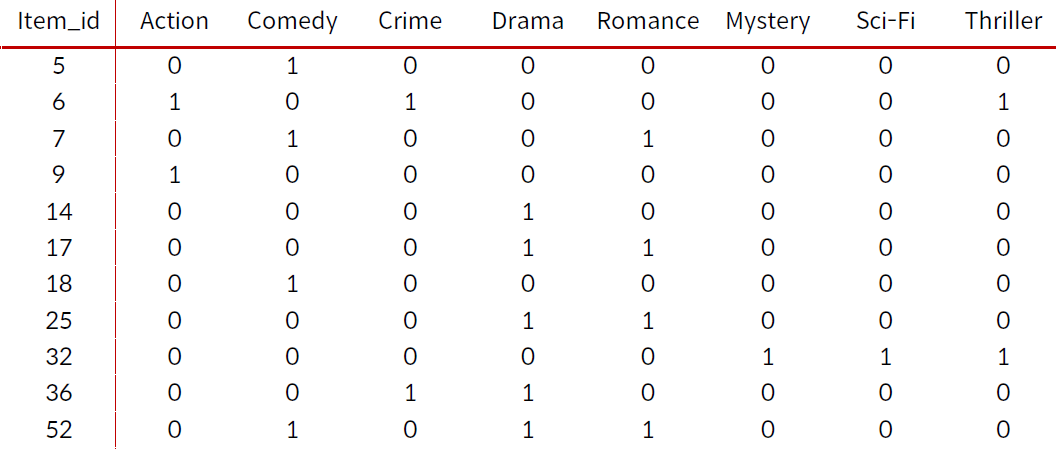
print("Items : ", matrix.shape[0])
print("Genres: ", matrix.shape[1])
- 각 item들에 대해 weight 구하기
totalItems = matrix.shape[0]
totalGenres = matrix.shape[1]
weights = np.zeros(matrix.shape)
for i in range(0, totalGenres):
col = matrix[:,i]
df = col.sum() # document frequency
idf = math.log10(totalItems/df)
for j in range(0, totalItems):
weights[j, i] = matrix[j, i] * idf
weights
- l2 norm 구하기

def norm2(arr):
sum = 0.0
for i in range(0, len(arr)):
sum += arr[i] * arr[i]
return math.sqrt(sum)
print(weights[0], "=>", norm2(weights[0]))
print(weights[1], "=>", norm2(weights[1]))
- 내적(Inner Product)

def dot(arr1, arr2):
sum = 0.0
for i in range(0, len(arr1)):
sum += arr1[i] * arr2[i]
return sum
print(dot(weights[0], weights[1]))
print(dot(weights[0], weights[2]))

- Cosine 유사도 구하기

def cosine(arr1, arr2):
return dot(arr1, arr2)/(norm2(arr1)*norm2(arr2))
print(cosine(weights[0], weights[1]))
print(cosine(weights[0], weights[2]))
- Numpy를 활용하여 Cosine 유사도 구하기
# Numpy Version
from numpy import linalg as LA #선형대수
norms = LA.norm(weights, ord=2, axis=1)
dots = np.matmul(weights, weights.T)
sims = np.divide(np.divide(dots, norms).T, norms)
활용 함수 정의
movies_w_imgurl.csv 활용 영화 포스터 display 함수 정의
#%run liblecture.py # 이후 liblecture 파일 실행 후 함수 사용
from IPython.display import display, HTML
def displayMovies(movies, movieIds, ratings=[]):
html = ""
for i, movieId in enumerate(movieIds):
movie = movies[movies['movieId'] == movieId].iloc[0]
html += f"""
<div style="display:inline-block;min-width:150px;max-width:150px; vertical-align:top">
<img src='{movie.imgurl}' width=120> <br/>
<span>{movie.title}</span> <br/>
{f"<span>{ratings[i]}</span> <br/>" if len(ratings) > 0 else ""}
<ul>{"".join([f"<li>{genre}</li>" for genre in movie.genres.split('|')])}</ul>
</div>
"""
display(HTML(html))
displayMovies(movies, [1, 2, 3], [4, 3, 3])
MAE, RMSE 구하는 함수 정의
import numpy as np
import math
def getMAE(real, pred):
errors = real - pred
return errors.abs().mean()
def getRMSE(real, pred):
errors = real - pred
return math.sqrt(errors.pow(2).mean())mat = np.array([
[1, 2, 3], # movieId
[3.0, 4.0, 5.0], # rating
[3.2, 3.8, 4.3] # prediction
])
ratings = pd.DataFrame(data=mat.T, columns=['movieId', 'rating', 'pred'])
mae = getMAE(ratings['rating'], ratings['pred'])
rmse = getRMSE(ratings['rating'], ratings['pred'])
print(f"MAE : {mae:.4f}")
print(f"RMSE: {rmse:.4f}")
Content-based Movie Rating Estimation

- genres 컬럼 split 후 한 컬럼으로 stack 하기
movieGenres = pd.DataFrame(data=movies['genres'].str.split('|').apply(pd.Series, 1).stack(), columns=['genre'])
movieGenres.index = movieGenres.index.droplevel(1)
- 각 genre별 count 후 idf 구하기
genres = pd.DataFrame(data=movieGenres.groupby('genre')['genre'].count())
genres.columns = ['movieCount']
totalItems = movies.shape[0]
#idf 값 구하기
genres['idf'] = genres['movieCount'].apply(lambda x: math.log10(totalItems/x))
genres.head()- 영화 장르와 idf 값을 join해서 DataFrame 생성
movieGenreWeights = movieGenres.join(genres['idf'], on='genre')
- MovieId별 장르의 idf DataFrame 생성
movieWeights = movies[['movieId']]
for genre in genres.index:
movieGenreIdf = movieGenreWeights[movieGenreWeights['genre'] == genre][['idf']]
movieGenreIdf = movieGenreIdf.rename(columns={'idf':genre})
movieWeights = movieWeights.join(movieGenreIdf)
movieWeights.fillna(0, inplace=True)
movieWeights
- 영화의 l2 norm 구하기
movieNorms = pd.DataFrame(data = LA.norm(movieWeights.iloc[:,1:].values, ord=2, axis=1), index=movieWeights.index, columns=['norm2'])- Normalize movie vector
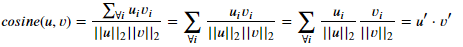
normalizedMovieWeights = movieWeights.iloc[:, 1:].divide(movieNorms['norm2'], axis=0)
normalizedMovieWeights
- 각 MovieId별 유사도 DataFrame 생성
sims = pd.DataFrame(data=np.matmul(normalizedMovieWeights, normalizedMovieWeights.T))
sims.index = movieWeights['movieId']
sims.columns = movieWeights['movieId']
sims
예측된 평점을 통해 영화 추천 - userid 한개 test
ratings = pd.read_csv('ratings-9_1.csv')
train = ratings[ratings['type'] == 'train'][['userId', 'movieId', 'rating']]
test = ratings[ratings['type'] == 'test'][['userId', 'movieId', 'rating']]
ratings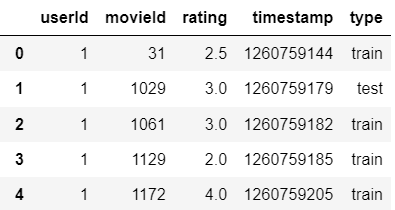
- 좋아하는 영화 Top 20 display
userId = 33
userRatings = train[train['userId'] == userId][['movieId', 'rating']]
#어떤 영화를 좋아했는지 나열해보기
topRatings = userRatings.sort_values(by='rating', ascending=False).head(20)
displayMovies(movies, topRatings['movieId'].values, topRatings['rating'].values)
-
recSimSums = sims.loc[userRatings['movieId'].values, :].sum().values
#유사도가 0인 애들로 인해 나오는 오류를 방지
recSimSums = recSimSums + 1
recWeightedRatingSums = np.matmul(sims.loc[userRatings['movieId'].values, :].T.values, userRatings['rating'].values)
recItemRatings = pd.DataFrame(data = np.divide(recWeightedRatingSums, recSimSums), index=sims.index)
recItemRatings.columns = ['pred']
recItemRatings- 좋아할 만한 영화 Top30 display
top30Movies = recItemRatings.sort_values(by='pred', ascending=False).head(30)
displayMovies(movies, top30Movies.index, top30Movies['pred'].values)- test 사용자에 대한 MAE, RMSE 계산
userTestRatings = pd.DataFrame(data=test[test['userId'] == userId])
temp = userTestRatings.join(recItemRatings.loc[userTestRatings['movieId']], on='movieId')
mae = getMAE(temp['rating'], temp['pred'])
rmse = getRMSE(temp['rating'], temp['pred'])
print(f"MAE : {mae:.4f}")
print(f"RMSE: {rmse:.4f}")
출처 : The RED : 현실 데이터를 활용한 추천시스템 구현 A to Z by 번개장터 CTO 이동주
'Learning > Recommendation System' 카테고리의 다른 글
| 03-2. Best Recommendation (0) | 2022.06.02 |
|---|---|
| 03-1. E-commerce 상품 추천(트랜잭션 데이터 기반) (0) | 2022.05.16 |
| 02-3. CF 기반 평점 예측을 이용한 영화 추천 (0) | 2022.05.12 |
| 02-1. 평점 예측을 이용한 영화 추천_overview (0) | 2022.05.12 |
| 01. 추천시스템 개요 (0) | 2022.05.12 |


