08. 생성적 적대 신경망(GAN)
목차
8.1 GAN 구조
GAN(Generative Adversarial Networks) 모델은 서로 경쟁하는 2개의 신경망으로 구성
- 생성자(generator) : 무작위 노이즈를 원래의 데이터셋에서 본 표본과 비슷하도록 변환하는 모델
- 판별자(discriminator) : 입력된 관찰이 생성자가 만든 가짜인지 원래의 데이터셋의 일부인 진짜인지 예측하는 모델
이해를 돕기 위한 예시
생성자는 위조지폐범 판별자는 경찰로 비유를 하자면 위조지폐범은 완벽한 위조지폐를 만들기 위해 노력하고 경팔은 이를 판별하기 위해 노력한다. 서로 상대방의 기술을 깨기 위한 방법을 계속해서 학습한다.
GAN의 동작 과정
- 생성자는 무작위 숫자를 입력받아 이미지를 변환한다.
- 생성된 이미지는 데이터셋에 실제 존재하는 이미지와 함께 판별자에 입력된다.
- 판별자는 실제 이미지와 만들어낸 가짜 이미지를 함꼐 입력받은 다음 각 이미지가 실제 존재하는 이미지일 확률을 반환한다. 0이면 가짜, 1이면 실제 이미지를 의미한다.

- Generator를 보면 합성곱 신경망 구조의 반대임을 알 수 있다. (학습 데이터에 포함된 이미지와 비슷한 크기가 될 때까지 업스케일링)
8.1.1 심층 합성곱 GAN(Deep Convlutional GAN, DCGAN)
: 판별자에 합성곱층을 사용한 버전(지금은 GAN도 DCGAN을 의미한다. -> 거의다 합성곱층 사용)
8.1.2 판별자(discriminator) 모델
- 입력 이미지가 생성자가 생성한 가짜 이미지인지 진짜 이미지인지 예측하는 것
- 분류 문제이기 때문에 판별자 신경망은 Conv층 뒤로 Sigmoid 함수를 사용하는 전결합층이 이어진 구조임
[Keras 구현 코드]
from keras.models import Sequential, Model
def discriminator_model():
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape= img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8)) # 학습시간 단축 및 정확도 향상
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape= img_shape)
prob = model(img)
return Model(img, prob)
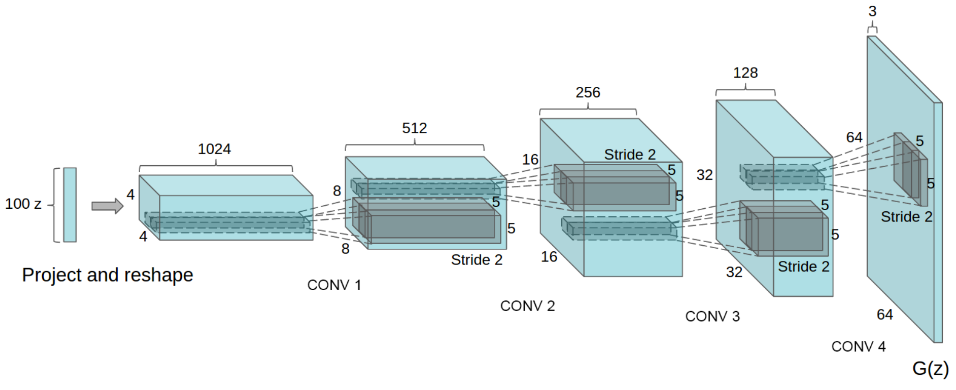
8.1.3 생성자(generator) 모델
- 무작위 데이터를 입력받아 훈련 데이터를 흉내 낸 가짜 이미지를 만든다.
- 입력이 1차원 벡터이다.
특징 맵의 크기를 키우는 업샘플링
- 특징 맵의 크기를 키우기 위해서는 입력 픽셀을 반복하는 형태로 늘리는 업샘플링 사용
- 생성자 모델은 훈련 데이터와 비슷한 크기가 될 때까지 업샘플링을 반복하도록 구성
keras.layers.UpSampling2D(size=(2,2))- 배율 (2, 2)를 적용한 업샘플링 예시
Input = 1, 2
3, 4
output = 1, 1, 2, 2
1, 1, 2, 2
3, 3, 4, 4
3, 3, 4, 4
[Keras 구현 코드]
def build_generator():
model = Sequential()
model.add(Dense(128 * 7 * 7, activation="relu", input_dim= latent_dim))
model.add(Reshape((7, 7, 128)))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(Conv2D(channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=(latent_dim,))
img = model(noise)
return Model(noise, img)
8.1.4 GAN의 학습
- 판별자 모델 학습 : 생성자 모델이 만든 가짜 이미지와 훈련 데이터에서 뽑은 진짜 이미지를 레이블과 함께 입력한다. 이후 이미지가 진짜인지 여부를 시그모이드 함수를 통해 확률값으로 예측한다.
- 생성자 모델 학습 : 모델이 만든 가짜 이미지가 얼마나 진짜 같았는지 알려줄 판별자 모델이 필요하다. 그래서 판별자 모델과 생성자 모델을 합친 통합 신경망을 구축하여 생성자 모델의 학습을 진행한다.

- 학습 중에는 다른 신경망의 학습 과정과 동일한 절차로, 학습 중 신경망의 성능 추이를 관찰하며 만족할 성능을 달성할 때까지 하이퍼파라미터를 조절
판별자 모델의 학습
- discriminator_model 메서드를 사용해서 모델을 만들고 컴파일
- binary_crossentropy를 loss function으로 사용하고 최적화 알고리즘 선택(ex. Adam)
discriminator = discriminator_model()
discriminator.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])# 무작위 데이터를 사용해서 학습을 진행하는 train_on_batch 메서드를 사용해서 배치 1개를 입력해 가중치를 한 번 수정하는 코드
noise = np.random.normal(0, 1, (batch_size, 100)) # 노이즈 데이터
gen_imgs = generator.predict(noise)
# 판별자 모델의 학습(가짜: 0, 진짜: 1)
d_loss_real = discriminator.train_on_batch(imgs, valid)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
생성자 모델의 학습(통합 신경망)

- 생성자 모델의 학습을 진행할 때는 판별자 모델의 가중치를 고정 -> 생성자 모델과 판별자 모델의 손실 함수가 서로 다르기 때문에 가중치 수정 방향도 서로 다르기 때문
generator = generator_model()
z = input(shape=(100,0)) # 무작위 노이즈
image = generator(z)
discriminator.trainable = False # 판별자 모델의 가중치 고정
valid = discriminator(img) # 생성된 이지미가 진짜일 확률 예측
combined = Model(z, valid)combined.compile(loss='binary_crossentropy', optimizer=optimizer)
g_loss = self.combined.train_on_batch(noise, valid) # 가짜 이미지를 진짜 이미지라고 생각하도록 생성자 모델을 학습
학습 에포크
- 한 에포크 마다 2개의 컴파일된 모델의 학습이 동시 진행(모델 성능도 동시에 향상된다.)
8.1.5 GAN 미니맥스 함수
인공지능 분야에서의 미니맥스 게임 이론
미니맥스는 의사 결정 알고리즘의 한 종류로, 두 명의 참가자가 순서대로 행동하는 게임의 의사결정에 주로 사용된다.(ex. 체스) 미니맥스 알고리즘의 목표는 최적의 다음 수를 예측하는 것이다. 한 참가자의 점수는 최대가 되게 하고, 다른 참가자의 점수는 최소가 되게 한다.
판별자 모델의 목표는 이미지의 레이블을 정확히 예측할 확률을 최대가 되게 하는 것이고, 생성자 모델의 목표는 생성한 이미지의 레이블이 정확히 예측될 확률을 최소가 되게하는 것이다.
8.2 GAN 모델의 평가 방법
- GAN의 생성자 모델의 학습은 이미지의 진짜, 가짜 여부를 판정하는 판별자 모델을 이용
- 생성자 모델의 학습에는 목표로 사용되는 손실 함수가 없으며 따라서 모델의 성능을 손실 기준으로 평가 불가
- GAN 모델의 성능은 생성자 모델이 만든 이미지의 품질을 사람이 직접 평가해야함
- 모델 개발 초기에는 사람이 직접 평가를 하고, 이후 여러가지 평가 기법을 적용해보는 것이 좋다.
GAN 모델의 성능을 사람이 직접 평가할 경우 겪는 어려움
- 학습 중 가장 성능이 높은 생성자 모델을 선택하거나, 학습 중단 시점을 결정하기 어려움
- 생성자 모델의 성능을 가늠하기 위한 이미지를 선택하기 어려움
- 서로 다른 구조의 GAN 모델의 성능을 객관적으로 비교하기 어려움
- 모델의 성능을 비교하며 하이퍼파라미터 및 설정을 미세 조정하기 어려움
-> 생성한 이미지의 품질과 다양성을 기반으로 정량적 방법과 정성적 방법을 결합한 평가 방법을 주로 이용(인셉션 점수, 프레셰 인셉션 거리)
8.2.1 인셉션 점수
: 실제 같은 이미지라면 실제 이미지를 사전 학습한 신경망에 입력하면 제대로 분류가 될 것이라는 휴리스틱한 컨셉
평가기준
- 생성된 이미지의 예측 점수가 높을 것 : 사전 학습된 인셉션 모듈에 생성된 이미지를 입력하고 그 분류 결과를 확인한 후, 분류 결과가 생성한 이미지와 어긋나지 않는다면 그 확신도를 해당 이미지의 예측 점수로 활용
- 생성된 이미지의 다양성이 높을 것 : 특정 클래스에 치우지지 않고 다양하게 이미지가 생성되었는지 확인
-> 두 가지 조건을 모두 만족하면 인셉션 점수가 높게 나온다.
8.2.2 프레셰 인셉션 거리(Frechet Inception Distance, FID)
- 입력 이미지를 인셉션 모델에 입력하는 방식을 사용
- 실제 이미지와 생성된 이미지를 분류 모델에 입력하고 그 출력을 모아 이들 값의 다변량 가우시안 분포를 구한 뒤 두 분포 사이의 프레셰 거리를 계산
- FID는 많은 수의 이미지가 필요함(5만 장 이상 권장)
- FID 점수가 낮을수록 실제 이미지와 생성된 이미지의 분포가 비슷. 즉 더 실제에 가까운 이미지를 생성한다.
8.3 GAN 응용 분야
8.3.1 Text to Image
: GAN 모델을 여러개 쌓은 StackGAN을 구성한 모델 활용
StackGAN 모델 동작 과정
- 주어진 문장의 내용에 따라 개략적인 형태와 색을 포함하는 저해상도 이미지 생성
- 1단계에서 생성한 이미지와 원래 문장을 입력받아 실제와 같은 고해상도 이미지 생성
8.3.2 Image to Image
ex. 회색조 이미지를 컬러로, 스케치 이미지를 실제로, 낮의 풍경 사진을 밤의 풍경 사진으로....등등
- pix2pix 모델 활용
- 판별자 모델이 원 이미지와 이를 바탕으로 생성된 이미지를 모두 입력받아 생성된 이미지가 원 이미지를 적정하게 변환한 것인지 판별
8.3.3 초해상도 이미징 GAN(Super-Resolution GAN, SRGAN)
: 이미지의 해상도를 향상시키는 방법
8.4 프로젝트: GAN 모델 직접 구현해보기
- Fashion-MNIST 데이터셋
- 5만 장의 훈련 데이터와 1만 장의 테스트 데이터로 구성된 회색조 이미지
- image_size : 28x28x1
1. 필요 라이브러리 임포트하기
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers import LeakyReLU # 수정됨
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
%matplotlib inline
from keras.datasets import fashion_mnist
from tqdm import tqdm
import numpy as np
2. 데이터셋 다운로드 및 확인
# Load the dataset
(training_data, _), (_, _) = fashion_mnist.load_data()
def visualize_input(img, ax):
ax.imshow(img, cmap='gray')
width, height = img.shape
thresh = img.max()/2.5
for x in range(width):
for y in range(height):
ax.annotate(str(round(img[x][y],2)), xy=(y,x),
horizontalalignment='center',
verticalalignment='center',
color='white' if img[x][y]<thresh else 'black')
fig = plt.figure(figsize = (12,12))
ax = fig.add_subplot(111)
visualize_input(training_data[3343], ax)# Rescale the training data to scale -1 to 1
X_train = training_data / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3)
3. 생성자 모델 구성
def build_generator():
model = Sequential()
model.add(Dense(128 * 7 * 7, activation="relu", input_dim= latent_dim)) # 전결합층
model.add(Reshape((7, 7, 128)))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D()) # 이미지 크기를 14x14로 늘림
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(Conv2D(channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=(latent_dim,))
img = model(noise)
return Model(noise, img)
4. 판별자 모델 구성
def build_discriminator():
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape= img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape= img_shape)
validity = model(img)
return Model(img, validity)
5. 통합 신경망 구성
# Input shape
img_shape = (28,28,1)
channels = 1
latent_dim = 100
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
discriminator = build_discriminator()
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
# Build the generator
generator = build_generator()
# The generator takes noise as input and generates imgs
z = Input(shape=(latent_dim,))
img = generator(z)
# For the combined model we will only train the generator
discriminator.trainable = False
# The discriminator takes generated images as input and determines validity
valid = discriminator(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
combined = Model(z, valid)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
6. 학습 과정을 담당하는 함수 구현
def plot_generated_images(epoch, generator, examples=100, dim=(10, 10), figsize=(10, 10)):
noise = np.random.normal(0, 1, size=[examples, latent_dim])
generated_images = generator.predict(noise)
generated_images = generated_images.reshape(examples, 28, 28)
plt.figure(figsize=figsize)
for i in range(generated_images.shape[0]):
plt.subplot(dim[0], dim[1], i+1)
plt.imshow(generated_images[i], interpolation='nearest', cmap='gray_r')
plt.axis('off')
plt.tight_layout()
plt.savefig('gan_generated_image_epoch_%d.png' % epoch)def train(epochs, batch_size=128, save_interval=50):
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random half of images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# Sample noise and generate a batch of new images
noise = np.random.normal(0, 1, (batch_size, latent_dim))
gen_imgs = generator.predict(noise)
# Train the discriminator (real classified as ones and generated as zeros)
d_loss_real = discriminator.train_on_batch(imgs, valid)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
# Train the generator (wants discriminator to mistake images as real)
g_loss = combined.train_on_batch(noise, valid)
# Plot the progress
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# If at save interval => save generated image samples
if epoch % save_interval == 0:
plot_generated_images(epoch, generator)
7. 학습 및 결과 관찰
train(epochs=10, batch_size=32, save_interval=1)
참고 : 비전 시스템을 위한 딥러닝(모하메드 엘겐디)
전체 코드 : https://github.com/moelgendy/deep_learning_for_vision_systems