07. Object Detection(R-CNN, SSD, YOLO)
목차
7.1 사물 탐지 알고리즘의 일반적인 프레임워크
- 영역 제안(region proposal) : 이미지에서 시스템이 처리할 영역인 RoI(Region of Interest)를 제안하는 알고리즘이다. RoI는 이미지 내 객체가 존재할 것이라 예상되는 영역을 의미하며 많은 수의 박스 정보 중 객체 존재 확신도가 높은 박스를 전달한다.
- 특징 추출 및 예측 : 각 박스 영역의 특징을 추출 및 평가해서 객체 존재 여부와 클래스 판단.
- 비최대 억제(Non-Maximum Suppression, NMS) : 같은 물체에 대한 중복된 박스를 탐지하고 하나의 박스만 남기기
- 평가 지표 : 평균평균정밀도(mean Average Precision, mAP), PR 곡선(Precision-Recall curve), 중첩률(intersection over union, IoU)
7.1.1 영역 제안
- 시스템이 이미지를 관찰하고 객체가 존재한가소 판단한 영역인 RoI를 제안
- 물체 확신도가 높은 영역은 다음 단계로 넘어가고 나머지는 폐기
- 신경망은 객체 확신도에 따라 전경(객체)과 배경(객체 아님)으로 나눔(임곗값에 따라)
7.1.2 특징 추출 및 예측
- 대개의 프레임워크에서는 사전 학습된 모델 중 일반화 성능인 높은 모델을 통해 특징 추출을 함
- 다음 두가지를 예측
- 경계 박스(Bounding Box) 예측 : 객체를 감싸는 박스의 좌표를 예측 (x, y, w, h), x, y는 중심점의 좌표, w, h는 박스의 너비와 높이
- 클래스 예측 : 해당 영역의 객체가 각 클래스에 속할 확률을 예측하는 소프트맥스 함수
- 사물 1개에 여러 개의 경계 박스를 예측
7.1.3 비최대 억제(NMS)
- 예측 확률이 가장 높은 바운딩 박스만 남기고 나머지는 배제하는 방식
- NMS 알고리즘의 작동 과정
- 예측 확률이 미리 설정된 신뢰 임곗값(confidence threshold)에 미치지 못하는 바운딩 박스 제거
- 남아 있는 바운딩 박스 중 예측 확률이 가장 높은 것을 선택
- 선택된 박스와 예측 클래스가 같은 박스의 중복 영역을 계산하고, 같은 클래스를 예측한 바운딩 박스끼리의 평균 중복 영역을 계산한다. (중첩률 IoU)
- IoU를 미치 설정한 NMS 임곗값에 미치지 못하는 바운딩 박스를 배제. 대개의 경우 0.5 정도로 설정
7.1.4 사물 탐지 성능 평가 지표
- 초당 프레임 수(FPS) : 탐지 속도의 평가지표
- 평균평균정밀도(mAP) : 0~100 사이의 값으로 나타내며 값이 클수록 성능이 좋음
- 각 바운딩 박스의 객체 존재 확신도 계산(객체가 존재할 확률)
- 정밀도와 재현율 계산
- 각 분류 클래스마다 확률의 임곗값을 변화시키며 PR 곡선 그리기
- PR 곡선의 AUC를 계산하여 AP 계산(각 분류 클래스마다 AP 계산)
- 각 클래스의 AP의 평균을 계산
- 중첩률(IoU) : 2개의 바운딩 박스(정답 박스, 예측 박스)가 중첩되는 정도를 나타내는 값으로 0(두 박스가 전혀 겹치지 않음)부터 1(두 박스가 완전히 겹침)까지의 값을 가진다.
- PR 곡선 : 정밀도, 재현율로 AUC를 계산하고 mAP를 통해 모델의 성능을 평가
7.2 영역 기반 합성곱 신경망
7.2.1 R-CNN이란
:합성곱 신경망이 물체 인식 및 위치 특정 문제에서 대규모로 응용된 최초의 사례
R-CNN의 네 가지 구성 요소
- RoI 추출기 : 영역 제안 모듈로 선택적 탐색 알고리즘을 이용해서 입력 이미지를 스캔하며 얼룩 패턴이 있는 영역을 찾아 다음 단계에서 추가 처리히도록 RoI를 제안(제안된 RoI는 고정된 크기)
- 특징 추출 모듈 : 합성곱 신경망 특징 추출기 사용
- 분류 모듈 : 기존 ML 알고리즘으로 분류기를 학습하고 특징 추출 모듈에서 추출한 특징으로 해당 영역의 객체 분류
- 위치 특정 모듈 : 바운딩 박스 회귀 모듈이라고도 하며 바운딩 박스의 위치와 크기 예측
선택적 탐색 알고리즘(이미지를 스캔해서 RoI 제안해주는 것)
: 물체를 포함하는 영역을 제안하는 데 사용되는 탐욕적 탐색 알고리즘으로 서로 비슷한 픽셀이나 질감을 가진 영역을 박스 영역 안에 모으는 방식을 통해 객체가 존재하는 영역을 찾는다.
그리고 완전 탐색 알고리즘(이미지 내 가능한 모든 위치를 탐색)과 버튼업 영역 통합 알고리즘(유사한 영역을 계층적으로 통합해가는 알고리즘)을 통해 가능한 모든 객체 위치를 감지한다.
1. 인접한 다른 모든 영역과의 유사도 계산
2. 가장 유사도가 높은 두영역을 통합
3. 객체 전체가 단일 영역이 될 때까지 이 과정을 반복
R-CNN 학습 절차
- 특징 추출 모듈로 사용할 합성곱 신경망을 학습(대개 사전 학습된 신경망을 미세 조정)
- SVM 분류기를 학습
- 경계 박스 회귀 모듈을 학습
R-CNN의 단점
- 사물 탐지 속도가 느림
- 학습 과정이 다단계로 구성되어 있음
- 학습의 공간 및 시간 복잡도가 높음
7.2.2 Fast R-CNN
기존 R-CNN에서 다음 두 가지 설계 수정을 통해 처리 속도와 정확도 개선
- 영역 제안 모듈로 파이프라인을 시작해서 그 뒤로 특징 추출 모듈을 배치하는 대신 CNN 특징 추출기를 맨 앞에 배치해서 전체 입력 이미지로부터 영역을 제안 -> 2,000개 이상의 중첩된 영역을 각각 처리하는 대신 전체 이미지를 하나의 CNN으로 처리 가능
- CNN에 SVM 분류기 대신 소프트맥스층으로 분류 수행 -> 하나의 모듈이 두 가지 일(특징추출, 사물 분류)을 할 수 있게 된다.
Fast R-CNN의 구조
- 특징 추출 모듈 : 신경망은 ConvNet으로 시작하여 전체 이미지에서 특징 추출
- RoI 추출기 : 선책적 탐지 알고리즘을 사용해서 약 2,000개 영역을 제안
- RoI 풀링층 : 특징 맵에서 전경합층에 입력할 고정 크기의 영역을 추출하는 역할
- 2개의 출력층
- RoI의 각 클래스에 속할 확률을 출력하는 소프트맥스층
- 최초 제안된 RoI와의 차이를 출력하는 바운딩 박스 회귀층
Fast R-CNN의 다중 과업 손실함수(multi-task loss)
: 객체의 클래스 분류와 바운딩 박스 위치 및 크기를 함께 학습하는 완결된 신경망 구조이므로 손실 함수도 이 둘을 함께 다루는 다중 과업 손실 함수여야 한다.
Fast R-CNN의 단점
성능 측정 시점에는 매우 속도가 빠르지만 영역 제안을 생성하는 선택적 탐지 알고리즘은 여전히 속도가 느리므로 큰 병목 지점이 남아있다.
7.2.3 Faster R-CNN
- 영역 제안을 위해 선택적 탐지 알고리즘 대신 영역 제안 신경망을 도입하여 영역 제안을 학습 과정에 포함함
- 예측 영역 제안은 RoI 풀링층을 사용하여 재구성되고 제안된 영역 내에서 이미지를 분류하고 바운딩 박스의 오프셋값 예측에 사용된다.
-> 영역 제안 수를 감소시켜 성능 측정 시점의 연산량을 줄임
Faster R-CNN의 구조
- 영역 제안 신경망(RPN) : 특징 추출기에서 생성한 특징 맵에서 추가 분석을 이어갈 RoI를 제안하는 역할(RPN 출력은 물체 존재 확신도와 바운딩 박스 위치)
- Fast R-CNN
사물 탐지 파이프라인 구성(신경망에 모두 내장시킴)
- 기본 특징 추출기 : 사전 학습된 CNN에서 분류기를 잘라낸 특징 추출기
- 영역 제안 모듈(RPN) : 사전 학습된 합성곱 신경망에서 만든 특징 맵의 정보를 기초로, 물체가 위치했을 법한 영역을 찾아내는 역할(선택적 탐색 알고리즘 대신 사용)
7.2.4 R-CNN의 정리
R-CNN은 실시간 사물 탐지를 실현하기 위한 노력의 결과이지만, 다음과 같은 단점으로 실시간 수준의 성능은 보기 힘들다
- 학습 과정이 번잡하고 시간이 오래걸린다.
- 학습이 여러 단계에 걸쳐 일어난다.
- 추론 단계에서 신경망의 속도가 느리다.
다단계 탐지기 : R-CNN은 2단계 탐지기임(RoI 추출, 분류)
단일 단계 탐지기 : SDD, YOLO(영역 제안 추출 단계를 건너뛰고 이미지내 가능한 모든 위치를 대상으로 직접 탐지를 시도하는 방식 - 정확도는 다소 떨어지지만 처리 속도는 훨씬 빠름)
7.3 싱글샷 탐지기
7.3.1 SSD의 추상적구조
: 피드 포워드 합성곱 구조를 가지며, 여러 개의 고정 크기 바운딩 박스를 생성하고 각 박스에 클래스별 객체 확신도를 부여한 다음 비최대 억제 알고리즘을 통해 최적 탐지 결과를 제외한 나머지를 배제한다.
SSD 모델의 구성
- 특징 맵을 추출하는 기본 신경망 : 분류기 부분을 제거한 사전 학습된 신경망 사용
- 다중 스케일 특징층 : 기본 신경망 귀에 배치된 합성곱 필터
- 비최대 억제 : NMS를 적용해서 물체별로 하나의 바운딩 박스만 남김
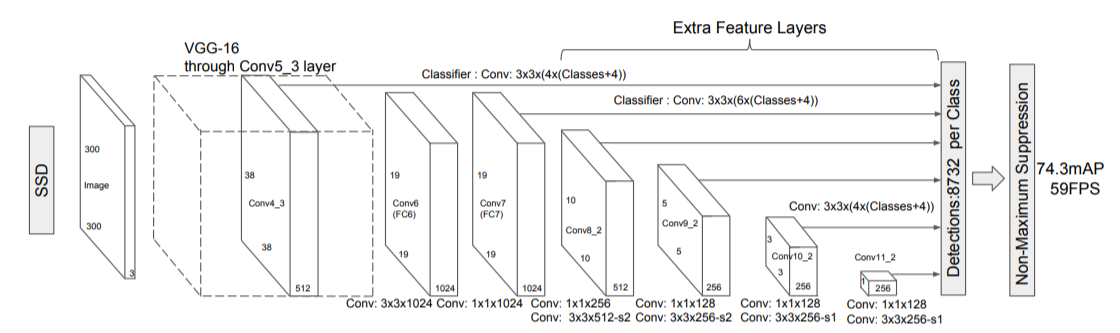
7.3.2 기본 신경망
분류기를 제거한 VGG16 사용
- 고해상도 이미지 분류에서 높은 성능을 보임
- 다양한 task에서 좋은 성과를 낸 모델
기본 신경망의 예측 과정
- SSD에는 R-CNN의 앵커 박스와 비슷한 역할을 하는 그리드가 있다. 각 격저점(Prior)마다 해당 앵커를 중심점으로 하는 경계박스를 생성
- SSD에서는 각 바운딩 박스를 별도의 이미지로 간주한다.
- 객체의 특징을 포함하는 바운딩 박스를 발견했다면 해당 박스의 예측 좌표와 사물 분류 결과를 NMS층으로 전달
- NMS 층은 정답과 중첩률이 가장 높은 경계 박스 하나만 남기고 다른 박스들은 배제
7.3.3 다중 스케일 특징층
기본 신경망 뒤로 이어지는 합성곱 층으로 합성곱 필터의 크기가 점진적으로 감소하도록 배치되어 다양한 배율로 예측 및 탐지를 수행할 수 있도록 한다.
다중 스케일 탐지
- 크기가 다른 객체를 모두 탐지하기 위해 다른 스케일의 앵커 박스를 활용
- 다중 스케일 특징층 수가 늘어날수록 정확도가 개선
7.4 YOLOv3
- 전체 처리 과정이 딥러닝으로 구현된 고속 사물 탐지 모델로R-CNN과 같은 영역 제안 단계가 없다.
- 입력을 소수의 격자 형태로 분할하고 분할된 영역을 대상으로 직접 바운딩 박스와 사물 분류를 수행
- 생성된 많은 수의 바운딩 박스를 NMS를 사용해서 최종 예측 결과로 좁힘
7.4.1 YOLOv3 처리과정
SxS개의 격자 모양으로 이미지 분할 후 정답 바운딩 박스의 중심이 어떤 조각에 포함된다면 해당 조각에서 객체의 존재가 탐지되어야한다. 이 방법으로 분할된 각 조각마다 B개의 경계 박스와 객체 존재 확신도, 객체 클래스를 예측한다.
- B개의 바운딩 박스를 결정하는 좌표
- 객체 존재 확신도 : 시그모이드 함수 사용(바운딩 박스하나 당 여러개의 클래스 존재 가능성이 있음. ex.여자, 사람)
- 물체의 클래스 분류 : 바운딩 박스에 객체가 포함되었다면 K개 클래스에 대해 객체가 해당 클래스에 속할 확률을 계산
배율을 달리하며 예측하기
- SSD의 앵커 개념처럼 이미지 조각마다 세 가지 다른 배율로 탐지를 시도하는 9개의 앵커가 존재
- 서로 다른 크기의 세 가지 특징 맵에서 각각 바운딩 박스를 하나씩 예측하므로 결과적으로 이미지 조각 하나당 3개의 바운딩 박스가 예측 결과로 나온다.
7.4.2 YOLOv3 구조
- 이미지넷 데이터셋을 학습한 53층 구조의 신경망(darknet-53) + 사물 탐지를 보조하는 53개의 층
참고 : 비전 시스템을 위한 딥러닝(모하메드 엘겐디)
전체 코드 : https://github.com/moelgendy/deep_learning_for_vision_systems