[AlexNet] ImageNet Classification with Deep Convolutional Neural Networks
Abstract
AlexNet : ImageNet Classification with Deep Convolutional Neural Networks
- 5개의 Conv층과 3개의 FC로 구성(6천만개의 파라미터, 65만개의 뉴런)
- 최종 층은 1000-way softmax
- 학습을 더 빨리 하기 위해 non-saturating 뉴런과 효율적인 GPU 구현을 사용했다.
- 과적합을 줄이기 위해 정규화 기법인 dropout을 사용했도, 매우 효과적이였다.
| contest | top-1 | top-5 |
| *ImageNet LSVRC-2010 | 37.5% | 17.0% |
| ImageNet LSVRC-2012 | 26.2% | 15.3% |
*1000개의 클래스로 분류된 120만개 고해상도 이미지
Index
- 1. Intoduction
- 2. The Dataset
- 3. The Architecture
- 4. Reducing Overfitting
- 5. Details of learning
- 6. Results
- 7. Discussion
1. Intoduction
모델 성능 향상을 위한 접근 방법
- 더 큰 데이터 셋 수집
- 더 강력한 모델 학습
- 과적합 방지를 위한 여러가지 기술
기존의 간단한 객체 인식은 비교적 작은 데이터 셋으로도 human performance에 접근하는것이 가능했다.
(예를 들어, MNIST 숫자 인식의 경우 최상의 에러율, <0.3%)
논문 기준 최근(2012)에는 대규모의 labeled 이미지 데이터 셋 수집이 가능해졌기 때문에, 이를 학습하기 위해서는 학습 능력이 큰 모델이 필요했다.
CNN의 장점
- 깊이와 폭을 변화시켜 제어할 수 있다.
- 이미지의 특성에 대해 강력하고 대부분 정확한 가정을 한다.
- 비슷한 크기의 층이 있는 standard feedforward 신경망에 비해 훨씬 적은 연결과 파라미터를 가지고 있다.
- 고해상도 이미지에 대한 높은 비용이 문제였지만 GPU로 해결
본 paper가 기여한 것
- 가장 큰 규모 중 하나의 CNN을 학습하여 대회에 사용된 ImageNet에 대해 최고의 성과 달성
- 2D 컴볼루션의 고도로 최적화된 GPU 구현과 공개적으로 사용할 수 있는 CNN 구현
- 모델의 성능 향상과 학습 속도 단축을 위한 새롭고 드문 방법 사용
- 과적합 방지를 위한 몇가지 효과적인 기술들
- 학습에 구현된 어떤 Conv층도 제거하면 성능이 떨어진다는 것을 확인
학습 환경 및 시간 : GTX 580 3GB GPU에서 5~6일 걸림
2. The Dataset
ImageNet
- 2만 2천개의 카테고리, 1,500만개의 labeled된 고해상도 이미지
- 아마존의 Mechanical Turk crowd-sourcing tool로 웹에서 수집되었고, 사람들이 레이블링함
- ILSVRC 대회는 1천개의 카테고리에서 약 120만개의 train-set, 5만개의 valid-set, 15만개의 test-set 사용
| error-rate | 의미 |
| top-1 error rate | 정답 레이블이 가장 확률이 높은 예측 레이블과 다른 비율 |
| top-5 error rate | 정답 레이블이 확률이 높은 5개의 예측 레이블과 다른 비율 |
ImageNet은 다양한 고화질의 이미지가 있기 때문에 256x256으로 re-sizeing을 함
(가로나 세로 중 짧은 쪽을 먼저 256으로 줄이고 CenterCrop)
각 픽셀을 Centerize하는 것 외에는 다른 전처리를 적용하지 않음
3. The Architecture

- 8개 층 - 5개의 컨볼루션층과 3개의 전결합층으로 구성
3.1 ReLU Nonlinearity
입력 x의 함수로서 뉴런의 출력 f를 모델링하는 표준 방법은 다음과 같다
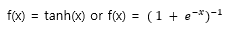
경사 하강법을 사용한 학습 시간 관점에서, 이러한 saturating nonlinearities는 Non-saturating nonlinearity 보다 훨씬 느리다.

- 이러한 nonlinearity를 가진 뉴런을 Rectified Linear Units(ReLUs) 라고 한다.
- ReLU를 사용하는 CNN은 tanh 단위를 사용하는 것 보다 몇 배 더 빠르게 훈련한다.
- saturating nonlinearities 함수 : input x가 무한대로 갈 때, 함수 f(x)의 결과 값이 어떤 범위 내에서만 움직이는 함수 ex. Sigmoid, Hyperbolic Tangent
- non-saturating nonlinearity 함수 : input x가 무한대로 갈 때, 함수의 결과값이 무한대로 가는 함수 ex. ReLU

- 해당 그래프를 확인해보면 tanh를 사용했을 때 보다 ReLU를 사용했을 때 수렴 속도가 개선된다.
- 더 빠른 학습 속도는 대규모 데이터 셋에서 모델에 큰 영향을 미친다.
3.2 Training on Multiple GPUs
- 하나의 GTX 580 GPU는 메모리가 3G밖에 되지 않아서 학습 가능한 네트워크의 최대 크기를 제한함
- 본 논문에서는 두 개의 GPU에 망을 분산한다.(GPU 병렬화)
- 이 방법을 통해 top-1, top-5 에러율을 1.7%, 1.2% 감소시켰고 2개의 GPU 넷이 훈련시간이 약간 더 적었다.
3.3 Local Response Normalization
- ReLU는 saturating 방지를 위한 input normalization을 요구하지 않는 바람직한 특성이 있다. 그러나, local normalization 구조가 일반화에 도움이 된다.
- ReLU는 양수값을 입력 받으면 그대로 출력하기 때문에 Pooling 등을 할 때 매우 높은 하나의 pixel 값이 주변의 pixel들에 영향을 준다. 이를 방지하기 위해 다른 활성화 맵의 같은 위치에 있는 픽셀끼리 정규화를 해준다.
- 이 정규화를 적용하여 top-1, top-5 에러율을 1.4%, 1.2% 감소시켰다.
3.4 Overlapping Pooling
- CNN의 풀링층은 동일한 커널에서 인접한 뉴런 그룹의 출력을 요약해준다.(전통적인 방식은 nonoverlap 방식)
- top-1, top-5 에러율을 0.4%, 1.3% 감소시켰다.

3.5 Overall Architecture
- 2,4,5번째 Conv층의 커널은 동일한 GPU에 있는 이전 층의 커널 맵에만 연결
- 3번째 Conv층의 커널은 2번째 계층의 모든 커널 맵에 연결
- ReLU의 비선형성은 모든 Conv층&FC층의 출력에 적용
- 첫 번째 Conv층은 크기가 11x11x3인 96개의 커널로 224x224x3 입력 이미지를 stride 4픽셀로 필터링
- 두 번째 Conv층은 첫 번째 Conv층의 출력을 입력으로 사용하고 크기가 5x5x48인 256개의 커널로 필터링
- 3,4,5번째 Conv층은 중간 Pooling 또는 정규화 층 없이 서로 연결
- 세 번째 Conv층은 크기가 3x3x256인 384개의 커널
- 네 번째 Conv층은 크기가 3x3x192인 384개의 커널
- 다섯 번째는 Conv층은 크기가 3x3x192인 256개의 커널
- FC층은 각각 4096개의 뉴런
4. Reducing Overfitting
4.1 Data Augmentation
- 이미지 데이터에서 과적합을 줄이는 가장 쉽고 흔한 방법은 label-preserving transformation을 사용하여 데이터 셋을 인위적으로 확장하는 것
- 약간의 코드로 디스크 저장 없이 이미지를 생성할 수 있으므로 계산이 필요하지 않다.(학습을 GPU에서 하는 동안 CPU에서 작업)
- 첫 번째 방법은 이미지 변형과 수평 반전
- 두 번째 방법은 이미지의 채도 변경
4.2 Dropout
- 0.5의 확률로 각 hidden 뉴런의 출력을 0으로 설정하는 것.
- dropout된 뉴런은 forward pass에 기여하지 않고 back-propagation에 참여하지 않는다.
- 한 뉴런이 다른 특정 뉴런에 의지할 수 없게 함으로써 뉴런간의 상호적응력을 감소시킨다.
- 따라서 다양한 뉴런의 조합을 사용하여 특징을 보다 더 강력하게 학습할 수 있다.
- test시에는 모든 뉴런을 사용했지만 출력에 0.5를 곱해서 사용을 했다.
- 첫 2개의 FC층에 dropout 적용
5. Details of learning
- batch-size : 128 / Momentum : 0.9 / weight decay : 0.0005 로 확률적 경사 하강법을 사용하여 모델 훈련
- 작은 양의 가중치 감쇠(단순한 정규화가 아닌, 모델 학습의 오류를 줄임)가 모델 학습에 중요하다는 것을 발견
- 표준편차가 0.01인 zero-mean Gaussian 분포에서 각 층의 가중치를 초기화
- 2,4,5번째 Conv층과 FC층에서 뉴런 bias 상수를 1(나머지는 0)로 초기화 (ReLU에 양수 입력을 하여 초기 단계를 가속화)
- lr은 0.01로 초기화하고 종료하기 전에 6번 감소시킴
6. Results
각 종 대회에 대한 정성/정량적인 평가(생략)
7. Discussion
- 층 하나를 제거하면 네트워크 성능이 저하된다는 인사이트를 얻음(예를 들어, 중간 층을 제거 했을때 2%정도의 손실이 발생함) -> 깊이는 결과에 중요한 영향을 끼친다.